Greetings from the team behind Chips of Fury! We've been on an exciting journey, crafting an online poker experience that is built with passion for the game and care for our players. In our quest to provide a pleasant gaming experience, we’ve conducted a detailed study of hosting providers out there. Fly.io was one of them - it is an infrastructure provider with a bunch of cool features, easy global accessibility, and more than reasonable hosting costs. Also, Chips and Sandwiches go great together, so we obviously went all in.
The experience has been great so far - Fly.io is a delight to use in most regards. There are a few caveats that we’ve discovered, however, and we would like to share them.

Now, let us deal the cards…
The issue at hand
When Chips of Fury players initiate a game, our orchestrator checks for available servers. Existing servers seamlessly host players, but due to obvious limitations, new servers must be started sometimes.
These newly spawned game servers, despite receiving the internal green light with regards to their health, exhibit a hesitation to promptly respond to external requests. This delay, as revealed by our benchmark data, probably surpasses the attention span of avid TikTok users (but do not quote us on that). This is a somewhat painful situation we have found ourselves in as a growing company - the long game server connection establishment might turn away new potential players, while always provisioning machines in all regions is a cost we would like to avoid.
The benchmark
Using Dart, the language Chips of Fury game servers speak, we created a straightforward script to collect some data on how long it takes for started servers to become responsive. It was kept running for 24 hours in regions crucial for us (ams, bos, cdg, dfw, hkg, iad, jnb, lhr, nrt, otp, scl, sin, sjc, and syd).
The application that the machines hosted is a basic HTTP server that has a few endpoints, including the essential /health. As to the numbers, we had two key metrics in mind:
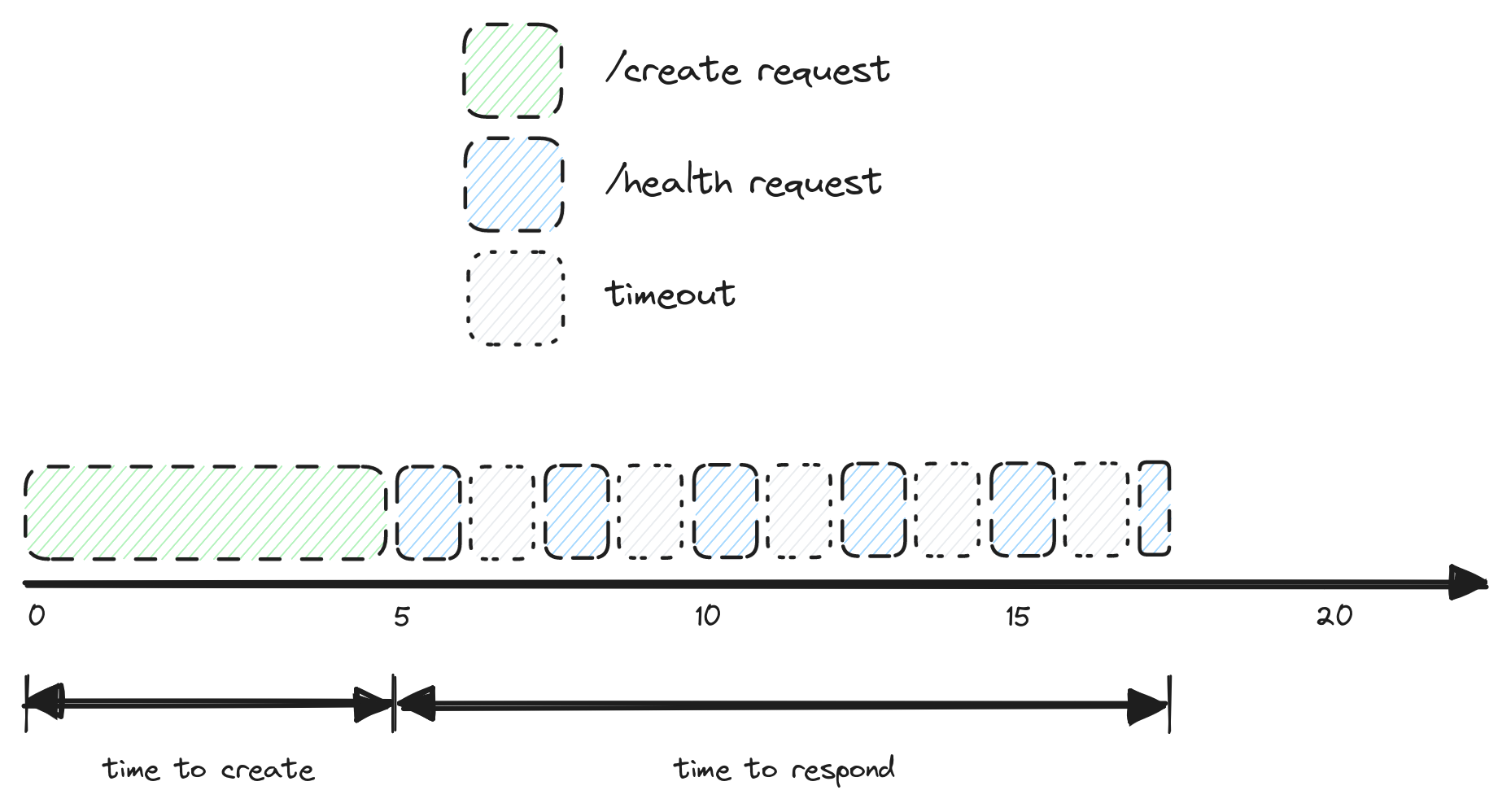
- The first metric collected was the time to start, which is the time between getting a response after issuing a request to create a new machine and this machine entering a "started" state (we use the /wait endpoint provided by Fly for that).
- Another metric is time to respond, which is the total time it takes before a newly started machine responds. Instead of hanging on a single request for however long it takes, we issue many of them. Each such request times out in a second, and another one is sent after another second. This was done after one of us found out that requests made very early on might never get to the instance.
Here are some numbers

For some reason, the lhr region was misbehaving that day. Since it would not be very fair to judge the machines’ quickness to become responsive, some outliers have been removed from the overall picture (but note that this data highlights the occasional instability of Fly.io which we are also unhappy with).

Even with the extreme values removed, the startup time varies a lot from region to region, but that is not the main concern here.
Instead, it is the response times observed across different regions that raise red flags: 20-30 seconds for the machine to become available to the public internet is very long for our specific needs. Remember: the time to become responsive to traffic outside of the Fly’s internal network is recorded after the machines enter a started state. It seems that the Fly.io networking takes time to catch up and start routing traffic to the instance, and as stated above, for the server to be unresponsive for upwards of 20 seconds after startup is too long for a game server.
You can look at the data yourself here and here. You might also find the Fly.io Dart client that we have open sourced useful.
Other caveats
In addition to this problem, there are a number of smaller issues that Fly has, such as an inconsistent dashboard, machines getting stuck in some states (even during this benchmark one machine stuck in the "starting" state and remains totally unresponsive until today), and very little failure recovery paths. The last one can be especially painful - our main admin application has completely stopped working because both instances dedicated to it became unhealthy, and not due to application error.
Something else that perhaps not only us would benefit from is some sort of real time notifications about machine status updates.
Thoughts?
While this analysis has shed light on the peculiar response times, it leaves us with lingering questions about the root cause. Our goal here is simple: share what we found, spark a conversation, and hopefully make the Fly.io experience better for Chips of Fury and everyone else.
Are there optimizations we've overlooked in our current infrastructure setup? Is there a possibility of unexpected behavior from the Fly.io proxy service? As we dive deeper into these mysteries, we invite the Fly.io community to join the exploration.